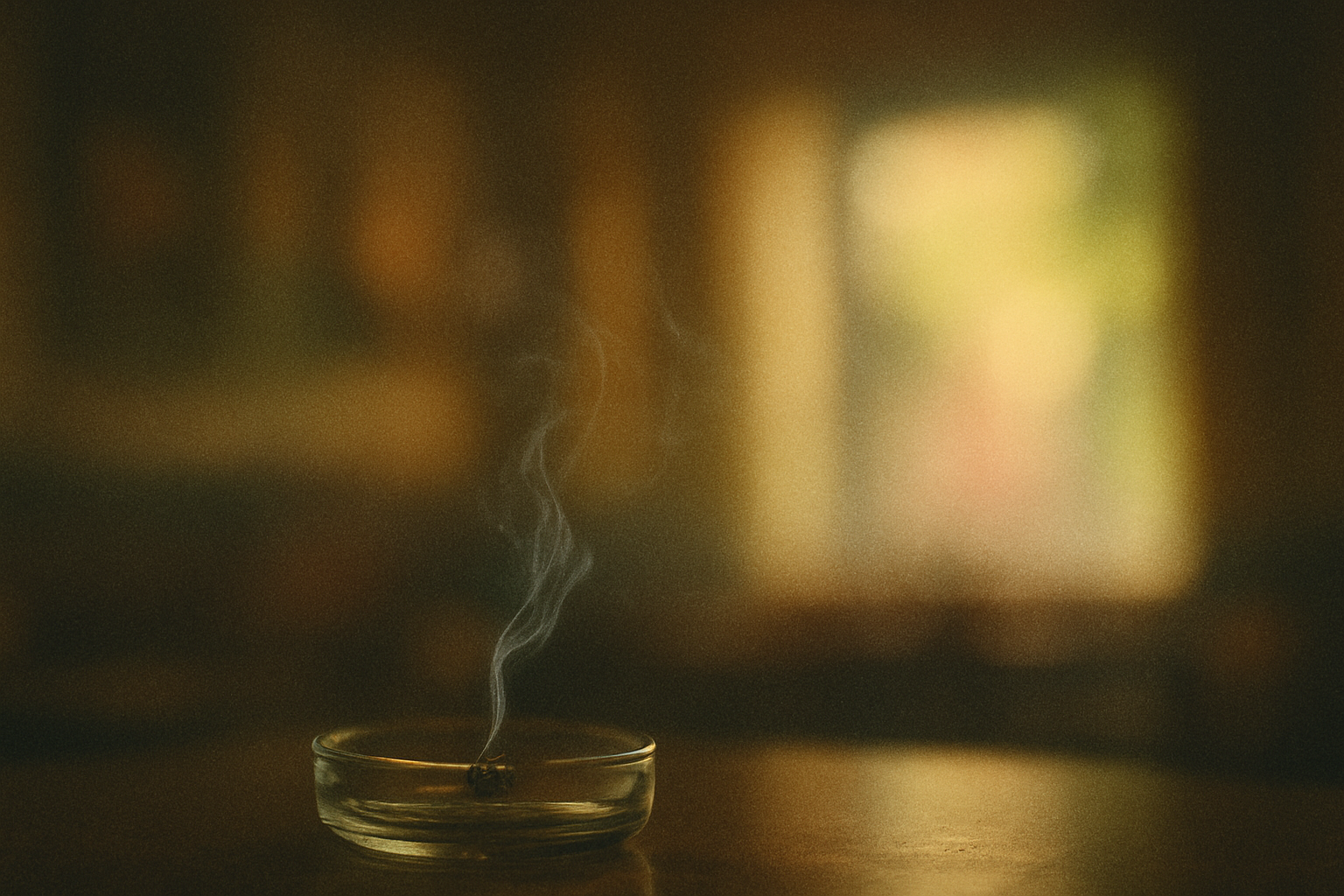
I write free-form text constantly. The typical result is a flow of poetry-like fragments and sequences. The starting point for this piece was one such free-writing fragment, which I later refined and trimmed down into this more polished version:
but, you know, most peculiar, how
painful
I used to love myself, with all the
teenage uncertainty, of course. but
still: just lower the pencil like
a needle onto the vinyl perimeter
& let the thoughts
crackle
or, maybe it was tobacco
an easy pleasure, so light, it was
hardly a pleasure at all
an excuse to watch people, with
dreams.
floating.
time.
passing. but without any
meaninglessness
there is something soulful in exhaling
smoke: a breath made
visible, like a poem half written. age
stiffens and cools everything, of course, but
sometimes I wonder
how much of the desire fades
with the shrinking of the future
You have to start somewhere
At first, I imagined I’d just make a simple Finnish version: I’d have ElevenLabs read the text aloud in my own cloned voicwe, glue a few AI-generated images on top of it, and call it a day.
Then I started thinking — maybe it would make sense to do the text in English while I was at it. Since I wasn’t entirely sure, I decided to begin with the visuals.
I first defined the style: we’d be going for a grainy, slightly faded photo aesthetic, something reminiscent of the 1990s. The mood should feel nostalgic and slightly aged. The text clearly took place in some distant past, back when people still smoked in cafés.
Next, I told ChatGPT what the images should depict. At first, I thought three images would be enough to cover the text. In hindsight, that feels idiotic—I’ve spent thousands of hours in editing, so I really should’ve known better. But you have to start somewhere.
The Eternal Struggle: Midjourney vs. DALL·E
I initially thought I’d create the images in Midjourney, since the quality difference has generally been clearly in its favor. However, I decided to give the newest built-in DALL·E model in ChatGPT-4o a chance. And right away, the first images felt so spot-on that there was no need for a contest.

So, on to production.
For the first image, I described a “slightly androgynous hand” in the foreground, holding a cigarette. Nothing else of the main character would be visible at this point. The background was to be softly blurred, with other café patrons just faintly present in the haze.
The same person would later appear visibly in another image, this time simply surrounded by cigarette smoke. (A mildly ironic line had been cut from an earlier version of the text, stating that “people shrouded in cigarette smoke have always looked good in photographs.”)
Between those two, I envisioned a simpler image: an old record player spinning an anonymous vinyl. It was the only image for which I had to revise the prompt. On the second try, I specified that the record player should sit on a wooden floor, viewed close-up, with a spacious room in the background flooded with summery light from the windows. To add a period detail, I pictured a yucca plant in the otherwise empty room—an interior touch true to the era’s aesthetic.

Hard Labor on the Street
While generating the images, I had already decided that the final piece would be done in English. From the AI’s perspective, this meant approaching the task from two angles: refining the original Finnish text, and at the same time crafting the best possible English version of it.
At this point, I was still thinking both languages would appear in the final video as conventional subtitles. That idea worried me, though—filling the screen with what was essentially secondary text content felt visually overwhelming. Besides, I wanted to preserve my original line breaks, at least partially. So I let the question simmer on the back burner for a while.
So I pasted the raw text into a new chat window and told the model I’d be working on it using voice input. Then I clicked on ChatGPT’s slightly annoying voice interface to get started.
It was one of the first warm summer evenings, so I moved my workspace outside, in front of the office. I poured myself a glass of rosé and carried out a folding chair. I couldn’t be bothered to bring a table or my laptop, so ChatGPT ran on my phone.
Stylistic Disputes and Content Refinement
The start went smoothly. I didn’t remember the lines by heart, so I instructed the AI to read a few at a time, after which I would tell it how to revise them. Each refined section would then immediately be turned into an English version as well.
ChatGPT didn’t have many objections to the language itself, although when working on the English translation, its background in formal writing became quite apparent. It kept trying to “fix” my mildly unorthodox line break technique — something I usually refer to, somewhat disrespectfully, with the entertainment industry term “cliffhanger.”
And although my flattery-prone bot companion was quick to praise the text in general terms, it couldn’t quite resist gently suggesting a few stylistic and content-related edits.
“myself, with the uncertainty of a teenager, but”
As an image, this is nuanced and deliberately open-ended. If you’re aiming for more compactness, a slight change in rhythm might bring added clarity:
myself—with the uncertainty of a teenager. But
Anyway, this is really a matter of taste—it also works well in its more airy, flowing form.
I usually didn’t agree to the bot’s suggestions. I felt my own versions were justified, and I didn’t want to settle for easier expressions. Maybe that was a mistake—but at least this way, the text still feels and tastes like mine. I believe it’s precisely those dozens of tiny decisions that ultimately determine whether the work’s aesthetic voice feels more like the AI’s or the human’s.
The visuals were mostly created by AI, but I made sure to prompt them thoroughly enough that I still consider myself the one who defined both the visual style and the direction. As for the text, I consistently held on to my own instincts.
At times, I did so even in English. For example, in the line that now reads “still: just lower the pencil / like a needle / onto the vinyl perimeter”, I insisted on using the word “perimeter.” The AI felt it “might sound a bit technical” and suggested smoother alternatives like “groove,” “edge,” or “surface,” with enthusiastic justifications. Those were perfectly reasonable choices—but I felt the slightly clinical “perimeter” added just the kind of formal detachment I wanted in that moment.
Was it the right call? Who knows. I can’t really evaluate that myself. But when it comes to artistic choices, I often find AI to be a risk-averse bureaucrat—and that just doesn’t work for the kind of art I want to make. I’ll listen to its ideas, and I’ll often weigh them carefully. But my art isn’t meant to be plain storytelling.

When the AI Forgets (On Purpose?)
One slightly troubling anecdote still lingers from the making of the text.
In the middle of our work, the scoundrel of an AI suddenly seemed to forget the first half of our session. I had to coax it — sometimes even snap at it a little (I am human, after all) — to return to the beginning of the text. But stubbornly, it kept starting from around the halfway mark, asking me again and again, “Would you like to make edits here, or shall we move on?”
That alone would’ve been annoying enough. But things got weirder.
When I later returned to the text transcript of our conversation, I noticed that the records of this particular disagreement were borderline gaslighting. I swear that in the voice interface, it kept looping over the same point again and again, yet in the transcript, most of my replies read simply: “No transcription available.” Occasionally, a snippet of my actual speech was preserved—cut off at random, poorly received—but just enough to prove I hadn’t hallucinated the entire argument:
“No, no. I don’t understand now why it ended up in that spot or why that kept repeating. Like the LinkedIn… the opening sentence of the intro. Read mine.”
The most unsettling part? Barely a third of that looped exchange seems to have survived. That’s really not OK. Sure, in this case we were just tweaking a piece of artistic content—but imagine an AI that alters the contents and development process of a political speech after the fact to better align with later consensus.
Of course, the most natural explanation is that something simply glitched during data transfer or processing. But that doesn’t explain why the AI itself completely lost track of the parts where it obsessively repeated old lines, and instead replaced them with cleaner, more “reasonable” responses. Some of my protests against the repetition are still visible, though—just enough to make the erasure all the more suspicious.
It all reeks of post-hoc polishing of the conversation history—and that’s deeply unsettling. Especially since, had this been a more serious matter, I probably wouldn’t be able to prove that anything went wrong at all.
In my view, there have been quite a few of these inexplicable, more-than-minor malfunctions with ChatGPT lately. I’d love to hear if you’ve encountered anything similar.
The Workhorse of Voiceovers
But enough of that. The text was now finalized and translated. It was time to turn it into voiceovers.
ElevenLabs has long been my go-to for generating speech—mostly because its voice clone integrates directly with Heygen. When I need to produce video avatars fast, I don’t have to leave Heygen: I get ElevenLabs’ top-tier, expressive voice performance embedded right in the workflow. For a busy publisher, that’s pure gold.
And once again, ElevenLabs didn’t disappoint.
It understands the emotional core of the text surprisingly well, and usually delivers an interpretation with just the right tone and rhythm. Or maybe my writing just happens to suit its processing style. Either way, technically, everything went smoothly.
The poetic format did pose some challenges—especially in terms of pacing. I had to insert non-standard punctuation to force the right pauses, but that’s still a basic step when working with expressive or lyrical texts. No complaints there.
Even the English performance by my voice clone worked out better than expected—better than I could’ve done myself, honestly. It sounded just foreign enough to signal that I’m not a native speaker, but without drifting into full-blown Euro-accent caricature.
The real problem was that, in the end, I didn’t quite like the sound of my own voice in this context. Oh well. Time for a voice swap.
After a few experiments, I settled on a female voice named Jen — almost exaggeratedly emotive, full of feeling. It took fewer than twenty tries to get the pacing and tone just right, and with that, the voiceover was nearly ready to be dropped into place.
Flat on My Back on the Couch, Again
I opened up my go-to mobile video editor, LumaFusion, and flopped onto the office couch with my phone in hand. These days, I’ve noticed that the vast majority of videos I end up posting on social media are made using this setup — this editor, this posture.
LumaFusion isn’t exactly the smoothest or most pleasant editor to use. But the simpler alternatives I looked into last time just didn’t offer the same level of control, especially when it comes to audio and even basic color correction tools. So for now, I’m sticking with LumaFusion.
The timeline devours images like a monster
This time, I started by slapping a roughly one-minute voiceover onto the timeline. Then I tried placing those three still images in position. It was immediately obvious that no amount of slow zooms or subtle in-frame movements would make it work.
At the same time, a realization began to crystallize: the text was so dense with imagery that, compared to moving images, it loses in quantity what it gains in nuance. This is one of the reasons why blending text and cinematic language is such a demanding task. It’s a rich topic, and one that I’ll return to in more detail another time.
So I had to start cranking out more images. Like an old slot machine finally paying out, the text generously handed me two key themes, with no metaphors or mental gymnastics required. The text itself mentioned a pencil being lowered onto paper, which had already been hinted at by the notebook on the protagonist’s table. The second theme was the café’s other customers, objects of both glances and distracted daydreams.
From the first theme, I generated one image showing a pencil tip touching paper, and another of just a blank page. I trusted the video generator to use them as a foundation for at least some kind of drawn animation or visual movement.
For the second theme, I created about half a dozen character portraits, along with a few images of full café tables. With AI-generated images, you don’t always get lucky, but this time, the yield was remarkably efficient: around 80% of the images made it into the final cut.
Runway Brought the Images to Life — Surprisingly Competently
Only after all these steps did I finally get to bringing the images to life.
After a brief moment of nostalgia-tinged deliberation, I decided to make use of my existing Runway account. No regrets there: at least with these images, the Gen-4 model delivered fantastic results; surprisingly advanced, as the final video clearly shows.
But there were still a couple of key problems to solve.
First, I decided to add a few sound effects: an exhale and the crackle of a vinyl record. Both sounds were generated in a matter of minutes using ElevenLabs’ sound generator. I think I ran two sets of four suggestions for each and picked one from both. Since the system didn’t quite produce the kind of satisfying record-sticking sound I wanted, I just made one manually—by duplicating a short section of crackle with the right kind of hiccup, back-to-back on the timeline.
Next, I ran all the still images through Runway’s Gen-4 model. I was stunned by the quality of the output.
Even though dazzling new competitors seem to pop up constantly in this space, Runway clearly hasn’t been standing still either. Besides, for me, Runway holds a certain nostalgia. It’s where I created many of my very first experiments with generative AI.
Closing Credits: That Went Pretty Well!
The repeating click of the record stuck on an empty crackle loop turned out to be the perfect audio motif to pace the end credits. So perfect, in fact, that I decided to ignore the credits now taking up about a third of the entire short film’s runtime. Still, I felt the sequence needed a visual anchor. I settled on an ashtray with a cigarette still smoldering. The dark background implied closing time. And it worked like a charm.
It’s hard to think of any other workflow where a single person could produce this much meaningful and aesthetic material in just a few hours. Whatever one thinks of generative AI, for small artistic projects it undoubtedly opens doors that would otherwise remain shut.
And here it is, the final video: